Md. Motahar Mahtab
Greetings!
I am Md. Motahar Mahtab, an AI Engineer and Applied Researcher with 3+ years of experience designing, training, and deploying intelligent systems across \textbf{NLP, Computer Vision, Reinforcement Learning, and Multimodal AI}. With a strong academic foundation (\textbf{CGPA 3.99}) and publications in top-tier venues (\textbf{NAACL, EMNLP}), I specialize in bridging research innovation with scalable engineering. My work spans building \textbf{multi-agent LLM pipelines}, \textbf{SOTA NLP models}, and \textbf{vision-driven information extraction systems}, along with architecting high-performance MLOps infrastructures leveraging \textbf{TensorRT, Triton, Kubernetes, and KEDA}. Passionate about developing efficient, reliable, and explainable AI systems that generalize across domains and modalities.
Experience
- Developed a Multi-Agent Data Extraction Pipeline for diverse files (PDF, DOCX, Code), outperforming general-purpose LLMs (Gemini 2.5 Pro, Claude Opus) by 15% on domain-specific extraction (e.g., dosing, covariates) and 10% on general extractions evaluated on 150 sources. Achieved 10% higher accuracy for large tables with >100 rows. Demo
- Designed the pipeline to automatically identify multiple fields from user queries, generate structured table outputs, and ensure correct data typing.
- Engineered an advanced paper layout system that improved Retrieval-Augmented Generation (RAG) performance by 12%.
- Trained a YOLOv11-based subfigure model (Global Average IoU: 0.8919) to decompose composite figures and extract metadata (captions, legends), boosting visual information retrieval.
- Enhanced image and table data with section-level metadata, captions, footnotes, and summaries to enable advanced image-based search queries (e.g., “Find breast cancer papers that contain drug name on the x-axis and dosage amount on the y-axis”).
- Created a production-grade Qdrant vector database containing 40M paper PDFs for scalable research paper retrieval.
- Engineered a novel image Bounding Box (BBox) filtering algorithm that reduced false positives by 34% through a dynamic minimum BBox size heuristic integrated into NMS filtering.
- Collaborated with pharmaceutical scientists to build an automated QC system for data cleaning and validation (unit standardization, column normalization, biomarker validation, dosing range checks), improving data accuracy to 97%.
- Established scalable MLOps and secure deployment infrastructure for high-throughput inference services using Nvidia TensorRT and Triton Inference Server (TIS).
- Migrated long-running tasks to Celery with RabbitMQ (RMQ) for event-driven architecture and decoupled data transfer.
- Implemented event-driven autoscaling in Kubernetes (K8s) using KEDA to scale Celery worker pods dynamically based on RMQ queue length, ensuring stable throughput.
- Enforced Zero Trust Security architecture by isolating all cloud services into private networks and securing inter-service communication with VPC Endpoints and S2S tokens.
- Achieved SOTA in Low-Resource Bangla NLP (NER, POS, QA, Lemmatization), exceeding 90% KPI for all modules.
- Set new NER SOTA (81.85% Macro F1, +6% vs. prior SOTA, 90.49% Macro F1 on delivered dataset) and POS SOTA using a novel hierarchical voting mechanism among SLM predictions. Demo
- Delivered SOTA for QA (SQuAD-bn) using a novel loss function to balance null/non-null answers, outperforming prior SOTA by 6%. Demo
- Co-developed and open-sourced the first production-grade Bangla Lemmatizer (96.36% accuracy) and Emotion Recognition system. GitHub, Demo
- Engineered Advanced LLM Methodologies and Data Pipelines for complex generation and tagging tasks.
- Built GPT-4o inference pipelines (NER, Coref) using the ReAct prompting framework, matching fine-tuned model performance.
- Resolved severe class imbalance in sequence tagging using a sentence resampling pipeline and advanced loss functions (Dice, Focal, CurricularFace).
- Architected Core MLOps and Data Versioning Infrastructure to manage complete model and data lifecycles using DVC and MLflow.
- Pretrained a HuBERT model on Bangla ASR dataset for joint task of speech and speaker recognition pipeline using SpeechBrain.
- Assisted in enriching existing open source Bangla ASR datasets by adding more scripted audio and correcting existing annotation
- Helped students with different coding assignments and helped teachers in checking scripts.
- Assisted students in conducting research in various fields and submitting papers to conferences.
- Assisted Teachers in lab classes and helped students with different course materials during consultation hour.
Education
Publications
- Developed BanNERCEM, a novel context-ensemble method achieving a state-of-the-art (SOTA) macro F1 score of 81.85% on Bangla NER, outperforming previous approaches.
- Introduced BanNERD, the largest human-validated Bangla NER dataset (85k sentences, 0.88 IAA), which proved superior in cross-dataset evaluations.
- Paper BanNERD: Context-Driven Approach for Bangla Named Entity Recognition
- Code https://github.com/eblict-gigatech/BanNERD
- State-of-the-art Bangla Rule Based Lemmatizer which proposes a novel iterative suffix stripping approach based on the part-of-speech tag of a word.Shows superior performance than all previously published Bangla lemmatization methods on existing datasets.
- Paper BanLemma A Word Formation Dependent Rule Based Lemmatizer
- Code https://github.com/eblict-gigatech/BanLemma
- Supervisor Dr. Nabeel Mohammed, Dr. Ruhul Amin
- First Bangla Clickbait News Article Dataset containing 15,056 data instances. Investigated various semi-supervised learning methods and compared them with supervised learning methods to prove the former’s superiority.
- Paper BanglaBait: Semi-Supervised Adversarial Approach for Clickbait Detection on Bangla Clickbait Dataset
- Code https://github.com/mdmotaharmahtab/BanglaBait
- Supervisor Dr. Farig Sadeque
- Trained state-of-the-art Transformer networks in adversarial fashion using Generative Adversarial Network (GAN) to achieve superior performance when labelled dataset size is too small.First Bangla Paper to investigate the application of GAN-BERT on Bangla text classification tasks.
- Paper A GAN-BERT Based Approach for Bengali Text Classification with a Few Labeled Examples
- Supervisor Mr. Annajiat Alim Rasel
Projects
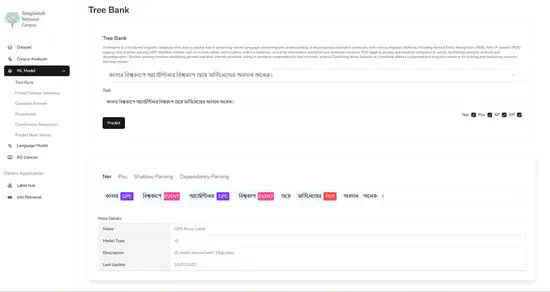
Bangla NER Classifier (FastAPI, Node.js, Tensorrt)
State-of-the art Bangla NER classifier. The underlying model is an XLM-RoBerta Large model trained on the largest Bangla NER dataset. It can detect 10 NER classes- 1. Person (PER), 2. Organization (ORG), 3. Geo-Political Entity (GPE), 4. Location (LOC), 5. Event (EVENT), 6. Number (NUM), 7. Unit (UNIT), 8. Date & Time(D&T), 9. Term & Title (T&T), and 10. Misc (MISC) with a macro f1 score of 90.49%.
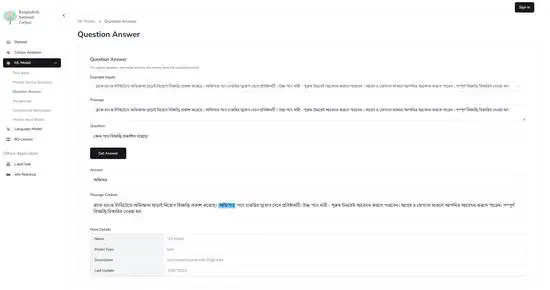
Bangla QA Model (FastAPI, Node.js, Tensorrt)
State-of-the art Bangla QA model. Given a passage and a question, it can accurately detect the correct answer span from the passage. The underlying model is an T5 model trained on Squad-bn dataset. It has achieved 83.71% F1 score which is 6% higher than previous best model.

Bangla Clickbait Detector (Pytorch, Streamlit, Node.js)
Demo app created as a part of research work on Bangla Clickbait Detection using GAN-Transformers. It takes a Bangla article title as input and outputs whether the title is a clickbait or non-clickbait along with the prediction probability score. GAN-Transformers is a Transformer network trained in a generative adversarial training framework.

Bangla Article Headline Categorizer App (Pytorch, Streamlit, Node.js)
Can categorize Bangla article headlines into eight different categories - Economy, Education, Entertainment, Politics, International, Sports, National, and Science & Technology. Models used State-of-the-art Bangla ELECTRA model, Dataset used Patrika Dataset - contains ~400k Bangla news articles from prominent Bangla news sites.
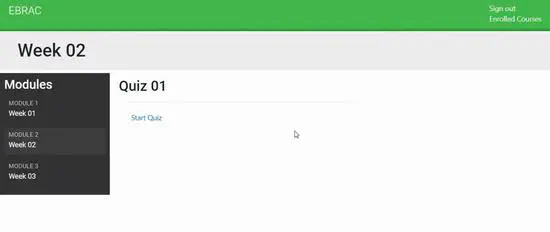
EBRAC - Online Learning App (Django, Bootstrap, Node.js)
A comprehensive online education platform where instructors can create different courses, upload course content, enrol students, see students’ marks, prepare questions, take quizzes etc. Students can enrol in courses, view course contents, participate in exams and see results.
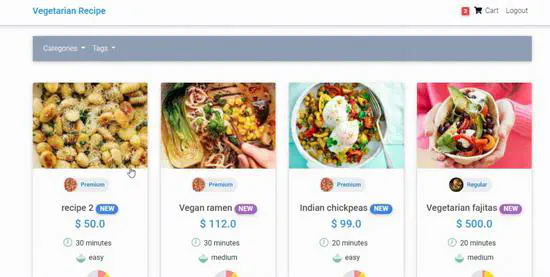
Veggie (Django, Bootstrap, Node.js)
This web app allows users to view different vegetarian recipes, and see their total calories, nutrients like protein, carbohydrate, fat and their ingredients. Users can create their own vegetarian recipes by mixing different ingredients available on the web app. They can also see the total nutrients and calories of their created recipe
Skills
90%
90%
90%
90%
95%
85%
80%
75%
90%
95%
95%
90%
80%
80%
80%
90%
90%
70%
70%
70%
90%
85%
80%
70%
Accomplish
ments
ments
Certifications
Open Source
Contributions
Contributions